Method
Four-stage pipeline
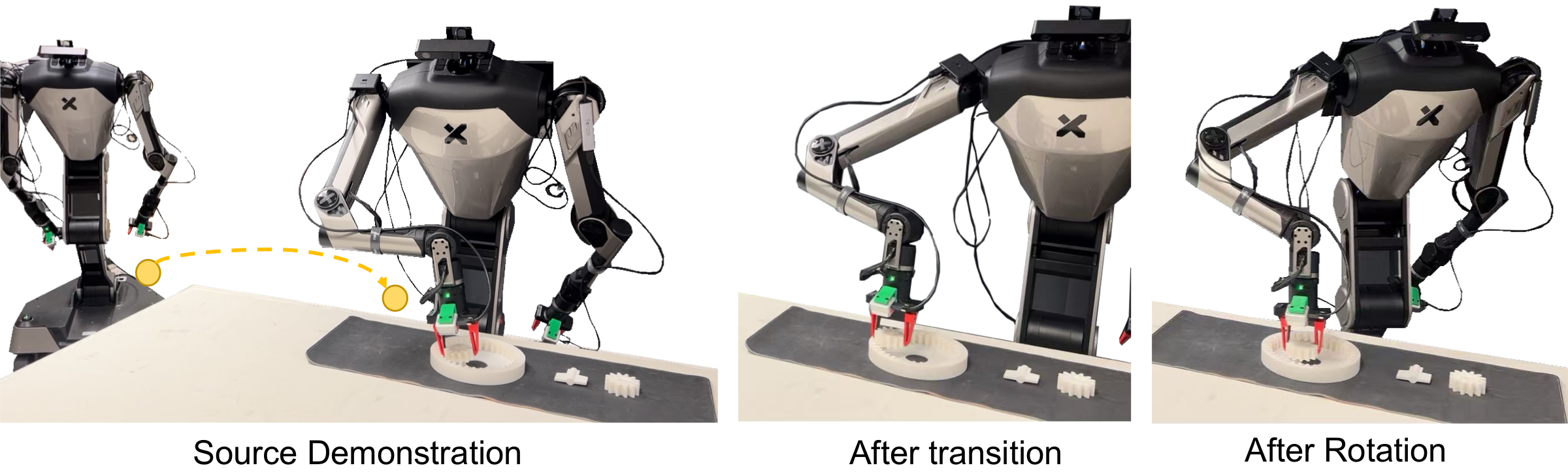
DockAnywhere transforms a source trajectory into target-docking-aware demonstrations through four sequential stages.
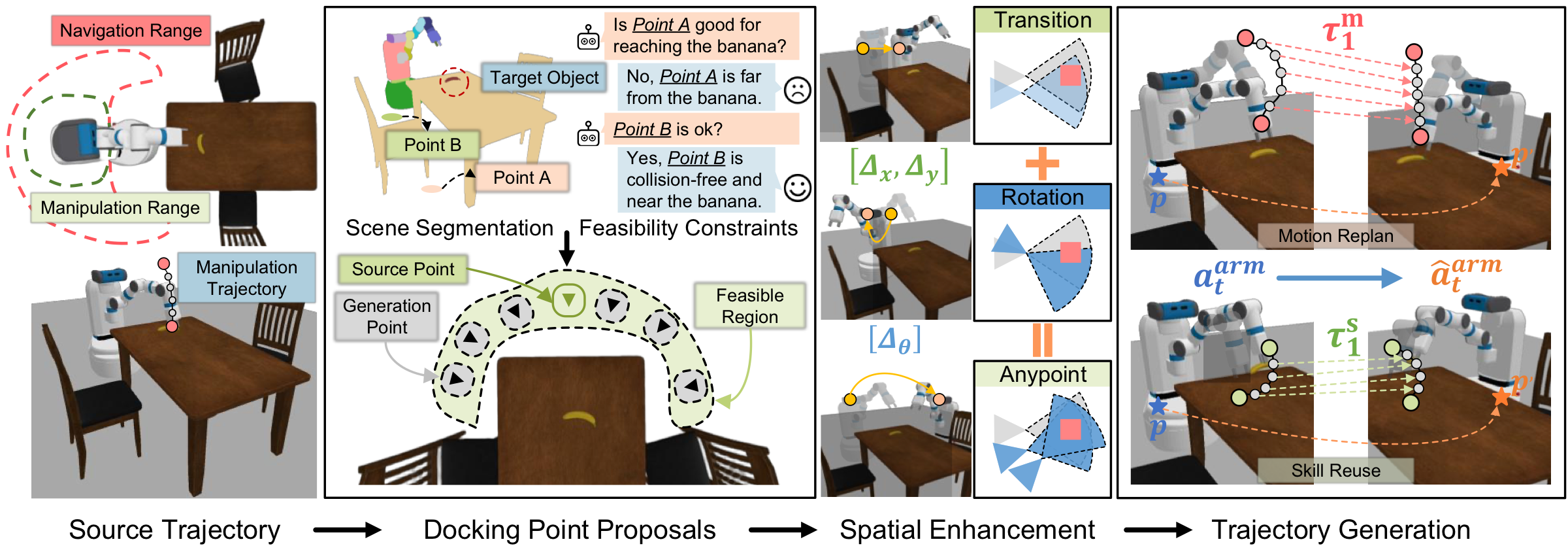
Pipeline overview. (1) The source trajectory and scene are segmented into manipulation range and motion range. (2) A VLM scores candidate docking points for feasibility against the target object. (3) Spatial transforms (Δx, Δy, Δθ) align the trajectory to the new docking pose. (4) Motion replanning and skill reuse generate the final augmented trajectory with synthesized point-cloud observations.
Stage 01
Trajectory Parsing
Each source demonstration is decomposed into a motion segment—the mobile base navigating to the docking point—and a skill segment—the arm executing the manipulation. This split enables independent transformation of the two segments under different spatial constraints.
Stage 02
TAMP-Based Docking Proposals
Candidate docking points are sampled along a feasible arc around the target object. A vision-language model (VLM) evaluates each candidate for collision freedom and reachability, filtering to a set of valid target docking configurations without any physical rollouts.
Stage 03 & 04
Spatial Transform & Observation Synthesis
A rigid transform (Δx, Δy, Δθ) maps the source skill trajectory to the target docking frame. The motion segment is replanned via standard navigation. Scene point clouds are edited geometrically—translated and rotated—to match the new egocentric viewpoint, producing a complete augmented demonstration with consistent 3D observations.